[스터디] 대규모 시스템을 설계하는 법
[가상 면접 사례로 배우는 대규모 설계 기초]의 책을 읽고 공부한 내용을 정리하는 글 입니다.
사진과 내용을 해당 블로그에서 많이 참고했습니다. 감사합니다:)
먼저 대규모 시스템을 설계하기 전에, 가장 태초의 단일 서버인 상황을 생각해보자

이 단일서버에서 우선 사용자는 도메인 이름 (www.mysite.com)을 이용해서 웹 사이트에 접속한다. 그러면 DNS가 웹 서버의 IP 주소를 반환해주고 해당 IP 주소로 HTTP 요청이 전달된다. 그 후 웹 서버로부터 HTML 페이지나 JSON 형태의 응답이 반환되는 구조이다.
해당 구조에서 사용자가 늘어나면 당연히 서버 하나로는 부족할 것이다. 그래서 데이터베이스를 담당하는 서버를 하나 추가한다.

데이터베이스는 크게 RDBMS, NoSQL 2가지로 나눌 수 있는데, 대체적으로 RDBMS로 해결할 수 있지만 아래와 같은 경우에는 NoSQL이 적절한 선택일 수 있다.
- 아주 낮은 응답 지연시간이 요구되는 상황 / 다루는 데이터가 비정형이라 관계형 데이터가 아닌 상황 / 데이터를 직렬화하거나 역직렬화할 수 있기만 하면 되는 상황 / 아주 많은 양의 데이터를 저장할 필요가 있는 상황
이제 조금 더 서버를 확장시켜보기 전에, 서버를 확장하는 방식에 대해서 알아보자.
크게 2가지 방식이 있는데 수직적 규모 확장과 수평적 규모 확장이다.
수직적 규모 확장(Scale Up) : 서버에 고사양 자원(더 좋은 CPU, 더 많은 RAM)을 추가하는 것
수평적 규모 확장(Scale Out) : 더 많은 서버를 추가하여 성능을 개선하는 행위
서버로 유입되는 트래픽의 양이 적을 때는 수직적 확장이 좋은 선택이며, 이 방법이 가장 단순하다. 하지만 수직적 규모 확장에는 한대의 서버에 CPU나 메모리를 무한대로 증설할 방법이 없고, 장애에 대한 자동복구(failover) 방안이나 다중화 방안을 제시하지 않아 서버에 장애가 발생하면 서비스는 완전히 중단된다는 단점이 있다.
위와 같은 이유로 대규모 어플리케이션을 설계하는데는 수평적 규모 확장법이 보다 적절하다.

위 방식은 로드밸런서를 이용한 수평적 규모 확장법의 예시인데, 로드밸런서를 통해 여러개의 서버를 배치한다. 사용자는 로드밸런서의 Public IP에 접속하고 서버 간 통신에는 Private IP가 이용된다. 로드밸런서를 통해 규모를 확장했을 때는 failover도 해소할 수 있다.
이제 데이터베이스를 다중화시켜보자.
트래픽이 늘어나면 당연히 쿼리도 늘어날거고 데이터베이스에도 부담이 가기 마련이다. 이때 데이터베이스도 다중화를 시킬 수 있는데 대표적인 방식이 Master-Slave 방식이다.

데이터베이스를 Master-Slave로 나누는데 쓰기 연산은 Master에서만 지원하고, 읽기 연산은 Slave에서만 지원한다. 대부분의 애플리케이션에서는 쓰기 작업보다는 읽기 작업이 훨씬 많기 때문에 Slave 데이터베이스가 훨씬 많다. 데이터베이스를 다중화하면 성능, 안전성, 가용성면에서 모두 이점이 있다.
다음은 캐시에 대해서 알아보자.
캐시는 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소이다. 애플리케이션의 성능은 데이터베이스를 얼마나 자주 호출하느냐에 크게 좌우되는데, 캐시는 그런 문제를 완화할 수 있다.

캐시가 어떻게 쓰이는지 간단하게 보자면,
- 우선 요청을 받은 웹 서버는 캐시에 응답이 저장되어 있는지 확인한다.
- 만일 캐시에 응답이 저장되어 있다면 해당 데이터를 클라이언트에 반환한다.
- 없는 경우에는 데이터베이스 쿼리를 통해 데이터를 찾아 캐시에 저장한 뒤 클라이언트에 반환한다.
위 흐름을 보면 캐시가 존재함으로써 데이터베이스까지 안가더라도 웹 서버에 응답을 줄 수 있기에 훨씬 빠르다는 장점이 있다.
하지만 캐시를 사용할 때 유의할 점이 있는데
- 캐시는 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 고려해볼만 하다.
- 영속적으로 보관할 데이터를 캐시에 두는 것은 바람직하지 않다.
- 캐시는 데이터를 휘발성 메모리에 두기 때문에, 캐시 서버가 재시작되면 모든 데이터는 사라진다.
- 만료된 데이터는 캐시에서 삭제되어야 한다.
- 만료 기한에 대한 정책을 마련하는 것이 좋다.
- 만료 기한이 너무 짧으면, 데이터베이스를 너무 자주 읽게 되며, 너무 길면 원본과 차이가 날 가능성이 높아진다.
- 데이터 저장소의 원본과 캐시 내의 사본 일관성을 확인해야 한다.
- 캐시 서버를 한 대만 두는 경우 해당 서버는 단일 장애 지점(SPOF)이 되어 버릴 수 있다.
- 캐시 메모리 크기는 너무 크지도 작지도 않게 적절하게 잡아야 한다.
- 캐시가 꽉 차버리면 LRU, LFU, FIFO 같은 정책들을 사용해서 사용해야 한다.
이러한 유의할 점을 꼭 체크하고 캐시를 사용하도록 하자.
위와 비슷한 성격으로 콘텐츠 전송 네트워크인 CDN에 대해서 알아보자. CDN은 지리적으로 분산된 서버의 네트워크이며 이미지, 비디오, CSS, JavaScript 파일과 같은 정적 컨텐츠를 캐시할 수 있다.

CDN이 적용되는 흐름을 보자면,
1. 사용자 A가 이미지 URL을 이용해 image.png에 접근한다.
2. CDN 서버의 캐시에 해당 이미지가 없는 경우, 서버는 원본 서버에 요청하여 파일을 가져온다.
3. 원본 서버가 파일을 CDN 서버에 반환한다.
4. CDN 서버는 파일을 캐시하고 사용자 A에게 반환한다.
5. 사용자 B가 같은 이미지에 대한 요청을 CDN 서버에 전송한다.
6. 만료되지 않은 이미지에 대한 요청은 캐시를 통해 처리된다.

이제 클라이언트와 서버 관계에서 서버가 클라이언트의 상태를 보존하는 방식에 대해서 알아보자.
만약 서버를 늘리는데 클라이언트의 상태를 보존하는 stateful한 상태에서는 무엇이 문제가 될까?
예를 들어 사용자 A는 1번 서버에서만 상태를 보존하고 있다고 하면 1번 서버가 갑작스런 장애가 생겨 다운되면 통신을 지속하지 못하는 상황일 것이다. 이러한 상황에서는 수평적 규모 확장법으로 서버를 여러대 증설하기가 까다로운 상황이므로 우리는 클라이언트와 서버의 관계를 보존하지 않는 stateless한 방식으로 설계를 해야한다.
다음은 데이터 센터에 대해서 알아보자.
장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되는데, 통상 이 절차를 지리적 라우팅이라고 한다.
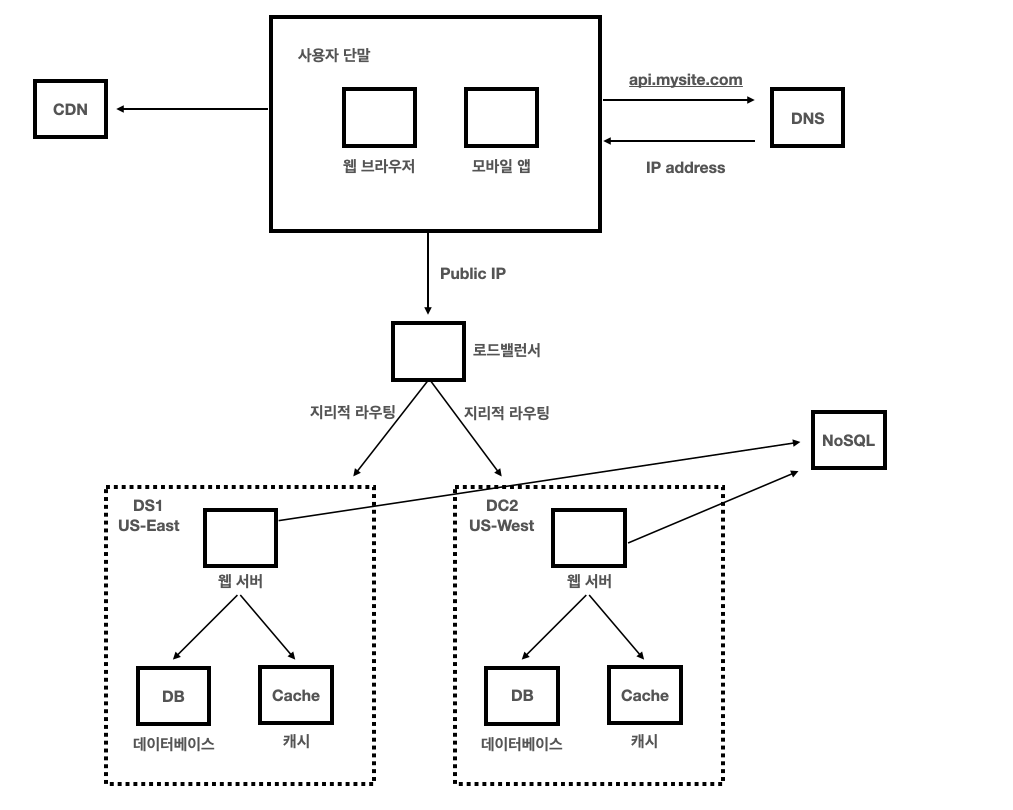
만약 데이터 센터 중 하나에 심각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
작년에 카카오 사건 같은 경우, 카카오는 자체 데이터 센터를 운영하지 않고 판교 SK C&C를 메인 데이터 센터로 두고 있었다. 그리고 이 비중이 40% 이상이어서 SK C&C에 화재가 발생해 데이터 센터의 전원이 차단되었고 나머지 데이터 센터로 모든 트래픽이 몰리면서 마비가 왔던 것이다!
다음은 메시지 큐에 대해서 알아보자.

메세지 큐는 메세지의 무손실, 즉 메세지 큐에 일단 보관된 메세지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성을 보장하는 비동기 통신을 지원하는 컴포넌트이다. Publish/Producer는 메세지 큐에 발행한다. 큐에는 보통 Consumer/Subscribe가 메세지를 꺼내서 동작을 수행한다.
메세지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋다.
마지막으로 데이터베이스의 규모 확장에 대해서 알아보자.

저장할 데이터가 많아지면 데이터베이스에 대한 부하도 증가한다. 이 때도 애플리케이션 서버처럼 스케일 업, 스케일 아웃 두 가지 방법이 존재한다. 데이터베이스에도 수직적 확장보다는 수평적 확장이 더 적절하다. 수평적 확장에 대표적으로는 샤딩이 있다. 샤딩은 대규모 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 기술을 말한다. 샤딩 전략을 구현할 때 중요한 것은 샤딩 키 이다. 샤딩 키에 따라서 한 곳으로만 부하가 집중될 수 있고 여러 곳으로 적절히 잘 분산될 수도 있다.
하지만 샤딩을 하기 위해선 필수적으로 고려해야할 조건들이 있는데,
- 데이터의 재 샤딩
- 데이터가 너무 많아져서 하나의 샤드로는 더 이상 감당하기 어려울 때
- 샤드 간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행될 때
- 유명 인사: 핫스팟 키 문제라고도 부르는데, 특정 샤드에 쿼리가 집중되어 서버에 과부하가 걸리는 문제
- 조인과 비정규화일단 하나의 데이터베이스를 여러 샤드 서버로 쪼개고 나면, 여러 샤드에 걸친 데이터를 조인하기가 힘들어진다. 이를 해결하는 한 가지 방법은 데이터베이스를 비정규화하여 하나의 테이블에서 쿼리가 수행될 수 있도록 하는 것이다.
위와 같은 조건들을 필수적으로 생각하면서 샤딩을 하도록 하자.

위 사진은 우리가 앞서 배웠던 설계 방식들을 모두 적용한 것이다.
개발자라면 이 일련의 과정들을 모두 공부해 자신의 프로젝트에 적용시켜본다면 엄청난 공부가 될 것 같다.